有开发者在 GitHub 上提供了可以导出微信聊天记录的项目,如 wechatDataBackup、WechatBakTool 与 WechatExporter ,但前两者要求使用版本低于 4.0 的微信,为此我尝试以旧版本微信(3.9.12)代替现版本微信(4.1.6),但发现仍然需要更新到最新版本才能进行登录。
最后,我通过使用 iTunes 在 Windows 备份 iphone 数据,随后使用 WechatExporter 项目中提供的应用程序才完成聊天记录的导出。
我的操作配置如下:
| 备注 | ||
|---|---|---|
| 电脑 | Windows11 | |
| 手机 | iPhone13 | |
| 数据线 | iPhone 原装 Lightning 充电线 | |
| 应用1 | 微信 | 移动应用端8.0.62 + 桌面应用端8.0.62 |
| 应用2 | iTunes | 桌面应用端 |
| 应用3 | WechatExporter.exe | 桌面应用端 |
| 应用4 | 爱思助手(视情况而定) | 桌面应用端 |
步骤 #
-
首先要成功连接 iPhone 与 iTunes。在 Windows 中下载 iTunes——我选择在 Microsoft store 中下载,但这要求将新应用的保存位置设置在 C 盘。下载好并打开 iTunes 后,用 Lightning 充电线连接 Windows 和 iPhone,此时 iPhone 界面会弹出是否信任的询问,选择「信任」并输入密码,正常情况下 iTunes 会显示连接的 iPhone 手机基本情况。
如果 Windows 上显示「iTunes 未能连接到此 iPhone,发生未知错误(0xE800000A)。」,可以先断开并退出 iTunes,下载爱思助手,然后重新连接 iPhone 和 Windows,接下来先打开爱思助手,同样在 iPhone 上进行授权,成功连接后再重新打开 iTunes,一般便可以成功连接。
-
第二步是将 iPhone 的数据备份到 Windows 中。成功连接 iPhone 与 iTunes 后,iTunes 会显示「备份」界面,选择「自动备份」一栏中的「本电脑」,同时不要勾选「加密本地备份」,最后点击「手动备份和恢复」下面的「立即备份」,耐心等待备份。
我昨晚在备份时不够耐心,以为卡住了,提前拔掉数据线,可等我重新连接 iPhone 和 iTunes 时,iTunes 不再显示「备份」这一界面,此时可以点开界面左上角导航栏的「文件」,依次找到
设备(V)>> 备份,再次点击「备份」即可。 -
最后是下载项目的执行软件,解压压缩文件后运行其中的 WechatExporter.exe。打开 WechatExporter.exe,如果 iTunes 已经将 iPhone 中的数据备份到了 Windows 中,应用界面会抓取到数据备份的地址。确认好 iPhone 数据备份在电脑的地址后,再设定好导出数据的地址,之后选取指定账号和相关聊天记录,最后点击「导出」即可。
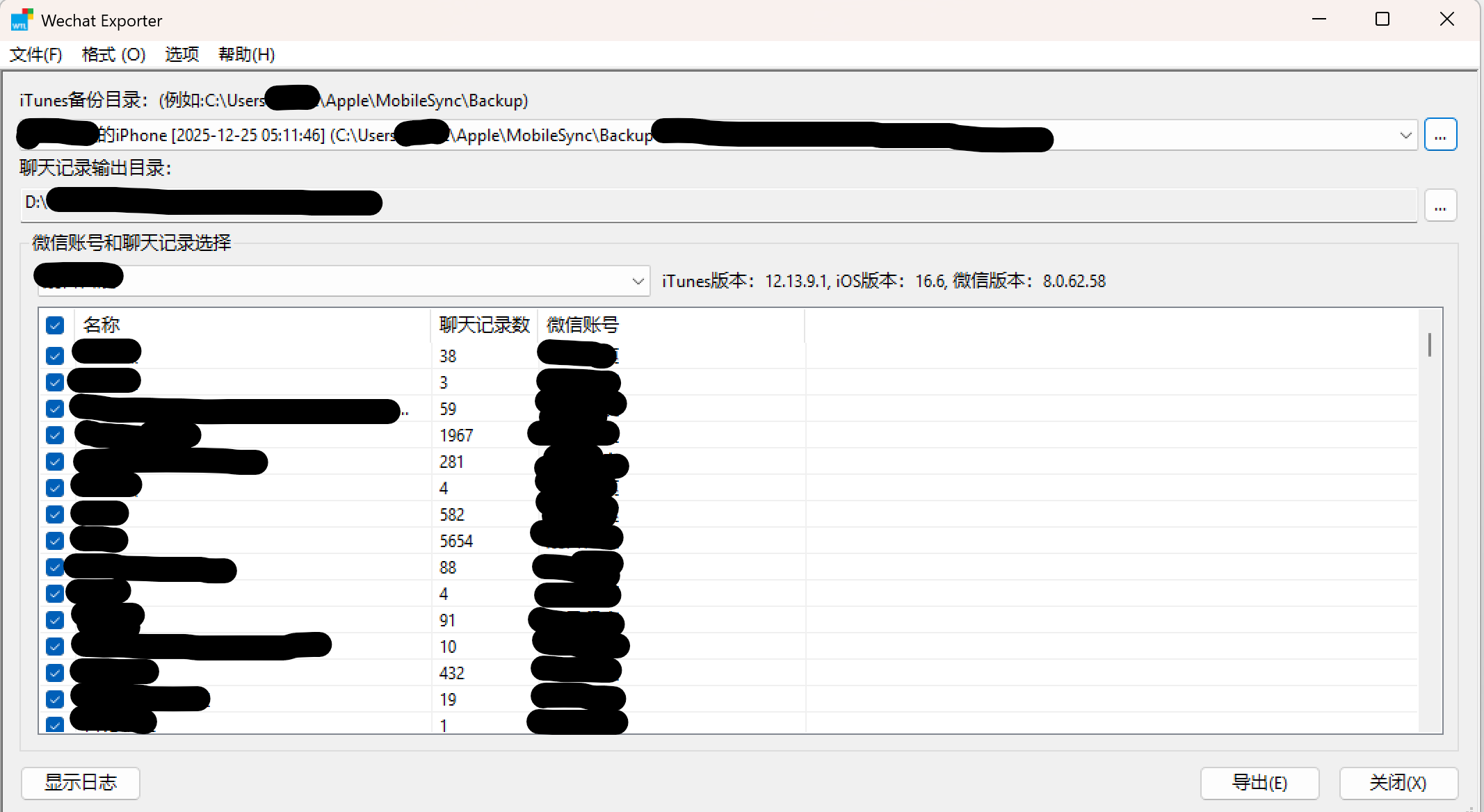
通常来说 iPhone 的数据备份位置在这里:
C:\用户[用户名]\AppData\Roaming\Apple Computer\MobileSync\Backup\……
但我的备份位置不一样,视具体情况而定。
C:\用户[用户名]\Apple\MobileSync\Backup\……
后话 #
WechatExporter 项目可以将聊天记录导出为 HTML、PDF 和 TXT 三种格式。这一项目最新的更新动态已经是 10 个月之前,期间微信应当也有了许多变化,因而导出的 HTML 内容中会缺少不少信息,例如链接、引用话语、表情包等的显示。
我使用 AI 对这部分聊天记录进行了个人性格与画像的分析,发现 AI 的概括和分析与我的认知基本吻合,甚至能发现一些我忽略的特点。相较而言,AI 对 HTML 的分析应当比对 PDF 的分析效果更好,而 TXT 则可能最好。
我想起之前在小红书刷到一位念语言学的文科博主当上了 NLP 算法工程师。NLP,自然语言处理,据闻是一种可以让计算机解释、操纵和理解人类语言的技术,可以对来自电子邮件、短信、社交媒体新闻源、视频和音频等通信渠道的大量语音和文本数据进行分类、排序、筛选、分析等,理解其中隐藏的意图或情绪。看起来,这似乎可以对齐商业用户研究。
我将自己的部分聊天记录喂给了 AI。

|

|
|---|---|
| 未确定我是谁 | 确定我是谁 |
在我看来,如果有更充足的分析资料,且文本提取方式和分析方法更为成熟,或许会得到更丰富的信息,就此而言,它在商业中可以发挥多大的作用,被如何想象?在此以外,一些出色的文学或人类学的文本「同样」是对人、社会、文化进行分析,但是分析的感觉又完全不一样。我不认为两者之间是否有所谓的优劣之分,只是看见和分析世界的方式不一样。那么,两者有交互的可能吗?两者之间发生碰撞会如何?不过这些都还只是我的臆想,一些感性、宽泛和缺乏实践的想象,写于此处,留下心中难得的疑问。
最后需要讲讲伦理的问题。在湘云的提醒下,我才意识到自己忽略了隐私。将微信聊天记录喂给大模型,帮别人训练了模型赚钱,此外,如果大模型得到足够的聊天记录进行分析,是否有可能导向大模型得以逐渐掌握数据提供者思想动态的可能?
独特的数据和注意力在当下都是稀缺资源。
无论是怎样的公司,哪怕是腾讯也不可以主动分析全国人民的数据,进而洞悉人们的想法和偏好。
因此,最终还是不建议打包和导出微信聊天记录这样的做法,至少不要打包自己以外的人的信息数据。即便是要分析自己的信息,也可以个人搭建一个开源模型,确保数据留在本地。AI 发展速度很快,但是关于伦理、隐私的保护意识、法律法规等似乎还都很薄弱,我们每天都在被大厂和算法窃取数据信息也不知其深远影响,甚至个人还在主动配合。